The components of order matching system have been previously discussed. Before reading this article, I recommend reading Anatomy of an Exchange: Understanding Order Matching System before reading this article.
When designing a matching engine, there are three key goals: performance, consistency and availability. These goals are often in conflict, so it is important to strike a balance between them.
Performance
Performance
Performance is the ability to process a large number of orders per second. This is important because the matching engine is the heart of any trading platform. If the matching engine is not fast enough, it can lead to delays in order execution, which can impact the profitability of traders. The biggest challenge of achieving high throughput in a matching engine is that order matching and cancel operations cannot be performed in parallel. This is because the result of one process affects the next process. Since operations are performed sequentially, when single operation is processed in 1 millisecond, it means that the matching engine can support 1000 transactions per second (TPS). However, if each operation takes 5 milliseconds, then the matching engine can only support 200 TPS. So, matching engine must be designed to minimize the amount of time it takes to process each order. These include:
- Using red black tree to store, match, update and cancel orders in memory
- Deploying different replica of matching engine for each trading pair using a kubernetes operator
- Utilizing a message queue to asynchronous all possible operations after the matches in order commands
Memory vs. Database
Memory vs. Database
The decision of whether to match orders in memory or in a database was one of the key decisions made when designing our matching engine.There are pros and cons to both approaches.
Storing orders in memory is faster than storing them in a database. This is because memory access is much faster than disk access. However, memory is also more expensive than disk space.
The decision to store orders in memory was made because achieving the highest possible performance was a priority. The performance benefits of storing orders in memory are considered to outweigh the associated costs.
Red-Black Trees
Red-Black Trees
Many data structure can be used to store and match orders. One of the possible data structures is sorted list. This is a simple and efficient data structure. However, the worst-case complexity of adding or deleting an order from a sorted list is O(n). This means that if the list is very large, then adding or deleting an order can be very slow.
Another common data structure is red-black tree. A red-black tree is a more complex data structure than a sorted list. However, the worst-case complexity of adding or deleting an order from a red-black tree is O(log(n)). This means that adding or deleting an order from a red-black tree is much faster than adding or deleting an order from a sorted list, even if the list is very large.
A red-black tree was chosen for matching orders to achieve better performance. The performance benefits of using a red-black tree are believed to outweigh the complexity of the data structure.
Using message queue:
Using message queue:
Events are published to Kafka message queue to make all of these operations asynchronous. All operations in the matching engine that do not require synchronization are delegated to Kafka consumers for asynchronous processing. This removes complexity from the matching process and boosts speed. The offloading of these operations to Kafka consumers allows the matching engine to run more efficiently, achieving higher TPS values with minimal strain during the operation
Scalability
Scalability
The matching engine performs each operation in memory for better performance. This means that matching can only be done in a single replica. However, this can also be a problem, because if the replica fails (node failure, termination because of insufficient vm resource etc), then all matching processes will be lost. To solve this problem, there are many options. Two best options are as follows
Option 1: Use a distributed lock mechanism and synchronize memory: This would allow multiple replicas to perform matching operations, and multiple replicas to have a copy of the order book in memory. But it would also add additional delay for lock and memory sync and make performance worse.
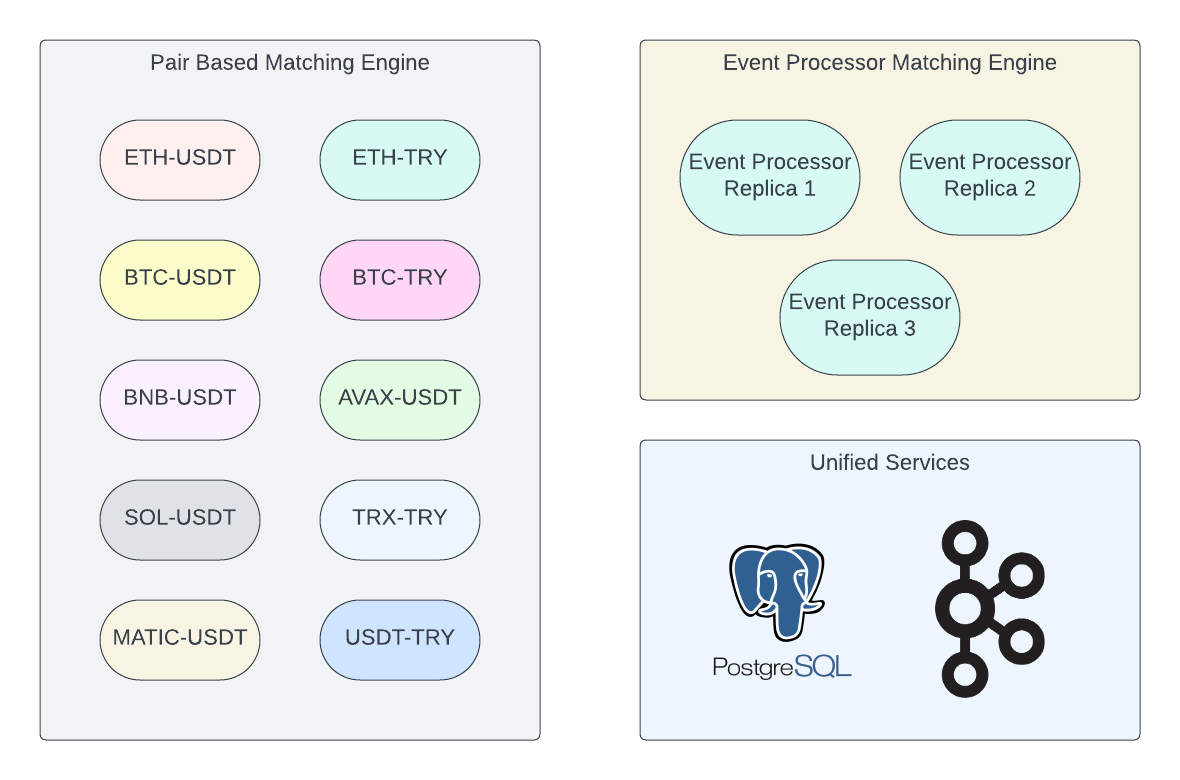
Option 2: Matching engine can be designed as each matching engine replica would be responsible for a single trading pair (ie ETH-USDT). This would allow us to provide more resources to the most used pairs and optimize resource usage.
The matching engine was designed to be pair-based. Also, event processor mode that updates the database from Kafka messages is developed. Multiple replica of event processor can be run, which allows us to achieve high performance and availability without sacrificing scalability.
Consistency
Consistency
Consistency is the property to always have the latest data available. This means that all orders must be matched correctly, and no orders should be lost or duplicated. Consistency is important because it ensures that traders have confidence in the system. Also, in case of node or disk failure, loss of data or matches can result in financial loss. To achieve consistency, database and message queue is used.
Utilizing a message queue to have message delivery guarantee
Utilizing a message queue to have message delivery guarantee
Kafka is used as a message queue. Each event generated by the matching engine is published to a kafka topic. Other services use these messages for balance and transaction management. Event processor replicas of the matching engine consume for these messages. Kafka guarantees that each message is delivered and processed at least once. This makes our system eventually consistent.
Using a database to store orders
Using a database to store orders
The event processor replica of the matching engine consumes each message on Kafka and updates the database. In case of matching engine restart, the replica responsible for matching waits for all Kafka messages to be processed and make sure that database is up to date. Then, it gets the order book state from the database. This operation is very fast and usually takes zero milliseconds, because in most case, the Kafka messages have already been processed.
Availability
Availability
Availability is the uptime of the matching engine. This means that the matching engine must be available 24/7, so that traders can trade at any time. Availability is important because it ensures that traders can execute their orders when they need to. In our matching engine design, Performance is prioritized, followed by consistency, then availability. The matching engine is optimized for speed, while still maintaining consistency and availability.
- Implementing fast recovery process when matching engine restarted
- Used Graalvm to minimize startup time of matching engine
- Use leader election mechanism to run pair-based replicas in multiple replica (This feature is in progress, we developed POC project and may publish another article after this mechanism is released.)
Conclusion
Conclusion
The matching engine design presented in this article represents a balance between performance, consistency and availability. The design prioritizes performance and consistency, and followed by availability. This means that the matching engine is as fast as possible and consistent, while still maintaining availability.
Final design of matching engine
The final design of the matching engine discussed in this article serves as a practical example. This design is currently utilized in a white label cryptocurrency exchange solution, named ‘Bluechange’, which is developed by Valensas and serves as the core of the Bitronit exchange. The design is not static and may be subject to evolution based on the specific requirements of the application. Consequently, the most effective design will invariably depend on the unique needs of each individual application.