Designing a payment facilitator platform on a PCI DSS–compliant Kubernetes orchestration is far more than simply deploying and managing container orchestration. Hosting a payment facilitator platform that complies with local regulations and PCI-DSS, requires meticulous and careful infrastructure design. This process demands that architectural design, network models, service communication, access patterns, and operational processes be structured directly in alignment with regulatory requirements. In this article, I share the end-to-end journey of the Kubernetes architecture we designed and implemented with PCI DSS compliance as a goal, the breaking points we encountered, and the critical architectural decisions we made along the way.
Translating Regulations into Architecture
Translating Regulations into Architecture
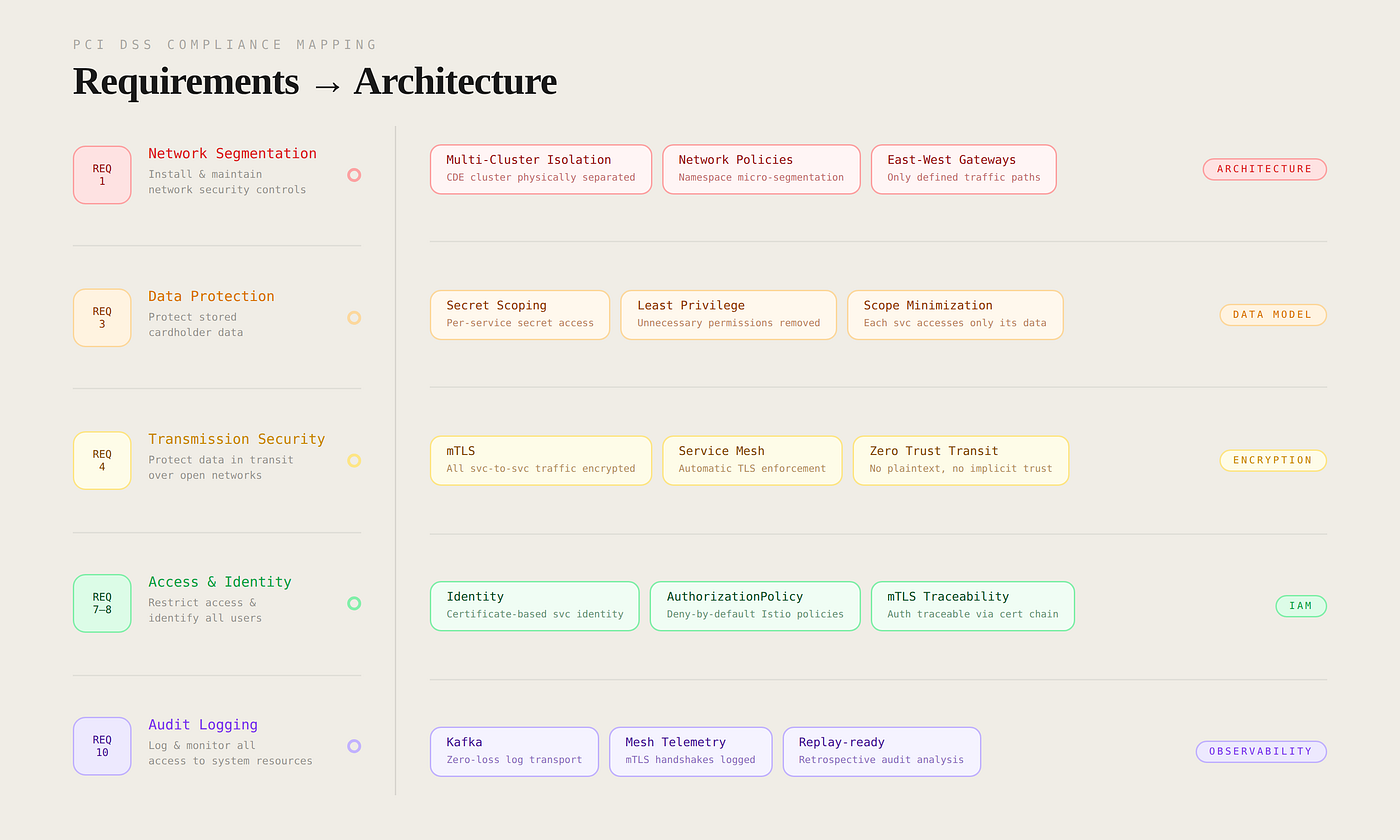
The first phase of the project was not selecting technologies, but understanding how to transform PCI DSS requirements into technical architecture. The following requirements in particular shaped the direction of the design: Requirement 1 — Secure network segmentation, Requirement 3 — Protection of cardholder data, Requirement 4 — Secure transmission of data, Requirement 7–8 — Access control and authentication, Requirement 10 — Logging and traceability. From the very first analysis, we realized that the platform architecture had to directly reflect regulatory boundaries.
The structure was not limited to Kubernetes clusters alone. The applications running on top of it directly influenced the regulatory design. Services were designed as non-monolithic, independently deployable, API-driven in communication, and built on a distributed microservice architecture. This approach had two critical impacts from a PCI perspective. First, scope separation: each service was positioned with its own data and access boundaries, allowing services touching cardholder data to be clearly isolated. Second, traffic control: inter-service communication became defined and traceable, making traffic management easier under Requirement 1 and Requirement 4.
From Single Cluster to Multi-Cluster
From Single Cluster to Multi-Cluster
Our initial approach was not multi-cluster. Within a single cluster, we planned to segment PCI workloads into separate Kubernetes network zones, apply micro-segmentation, and restrict traffic using network policies. With distributed microservices, this segmentation became more meaningful because traffic could be restricted by service identity, namespace scope, and business need. This model was technically compliant with PCI DSS Requirement 1.
Although the single-cluster design seemed sufficient, long-term licensing and regulatory plans reshaped the architecture. Future audits and licensing needs made it more sustainable to separate platform boundaries from the start. This approach aligned with PCI DSS Requirement 12 from a security governance and risk management perspective. As a result, we transitioned to a multi-cluster architecture.
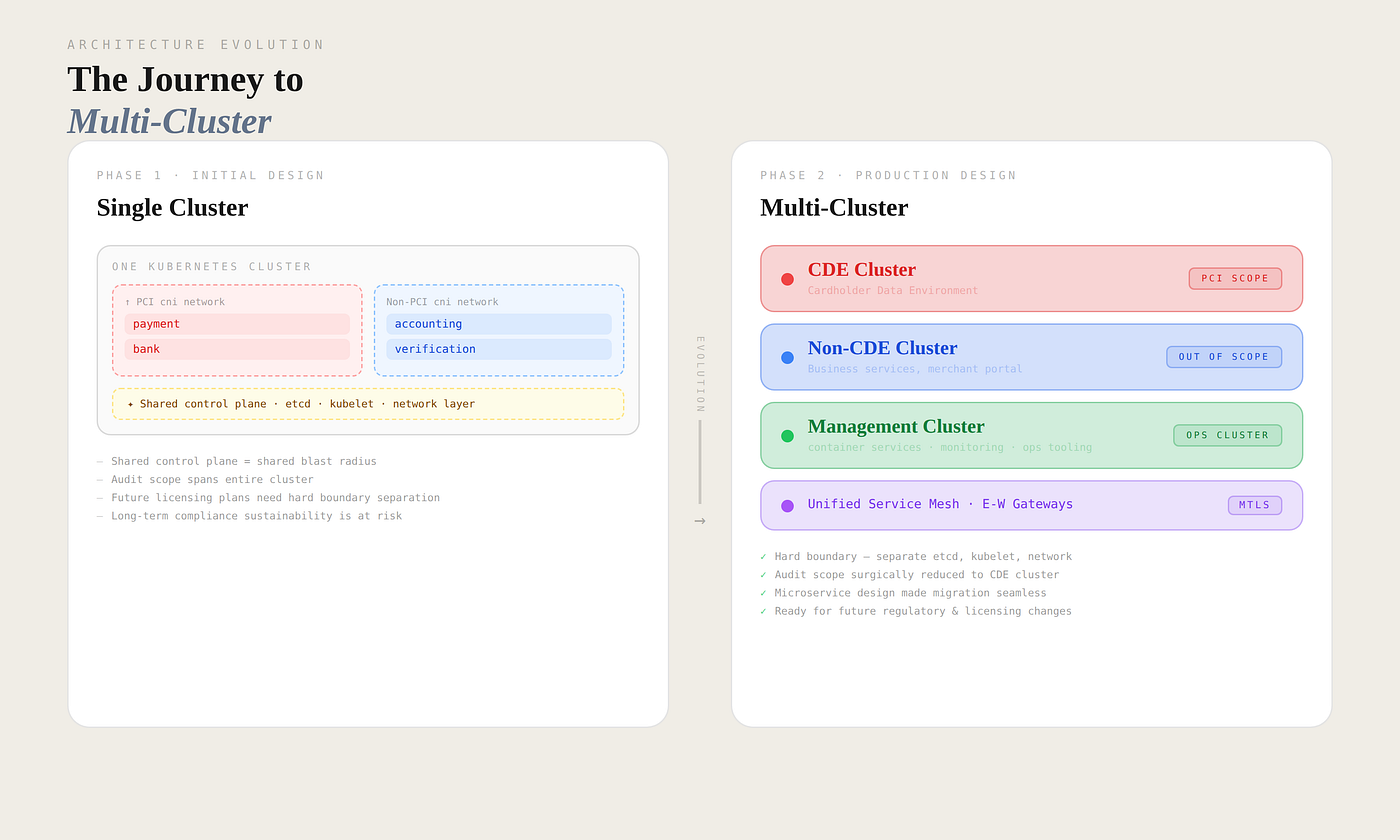
In the new model, PCI-scope services were placed in a separated cluster, while non-PCI services were positioned in a separate cluster. The distributed architecture again provided advantages. Since services were already loosely coupled, changing cluster boundaries did not disrupt application design.
Service Mesh, mTLS, and Zero Trust
Service Mesh, mTLS, and Zero Trust
Separating clusters was easy; establishing secure service communication was the real challenge. This was directly related to Requirement 4 because data moved between services, transmission had to be encrypted, and source identities had to be verified.
Both clusters were connected through East-West Gateways to a single service mesh control plane. Traffic was forced through gateways, direct pod access was blocked, and service discovery was handled via the mesh. This architecture created critical observation points for Requirement 1 and Requirement 10.
The most critical security contribution of the service mesh layer was mTLS. With mTLS, all service-to-service traffic was automatically encrypted, directly addressing Requirement 4. Each service was authenticated via certificate-based identity, satisfying Requirement 8. Unauthorized service calls were blocked, extending network segmentation into the application layer. In-cluster traffic was not trusted by default; access was explicitly defined via Authorization Policies. This Zero Trust model played a critical role in securely operating the microservice architecture.
Protecting cardholder data was handled not only at the storage layer but also through the service access model. Under Requirement 3 and Requirement 7, service-based secret access was defined, unnecessary permissions were removed, and scope was minimized. With the benefit of distributed model, each service accessed only the data it required.
In line with Requirement 8, service identities, platform access, and API calls were made traceable. mTLS identities also contributed to this observability.

Under Requirement 10, access and traffic logs were centrally collected. Collected data included Kubernetes API access logs, inter-service calls, and mesh traffic records. Kafka was positioned to ensure log consistency. With Kafka, log loss was minimized, high-volume data was transported reliably, and replay enabled retrospective audit analysis.
The distributed microservice model made observability as mandatory. Monitoring tooling enabled health monitoring, pod state visibility, and service availability tracking. Traffic analysis covered service call volumes, error rates, and latency metrics. Mesh visibility included mTLS handshake states and unauthorized traffic attempts. This observability supported monitoring and security analysis under Requirement 10 and Requirement 11.
Beyond mesh telemetry, analysis was also conducted at the network layer. Observed areas included East-West traffic flows, gateway transitions, and service access paths. This enabled detection and prevention of unexpected traffic and analysis of scope violations.
Under Requirement 6, deployment processes were pipeline-driven, version traceability was ensured, and approval mechanisms were established. This control became even more critical in a distributed architecture.
Physical security controls under Requirement 9 were evaluated within the framework provided by the infrastructure provider, and necessary adjustments were made accordingly.
Under Requirement 12, backup processes were addressed within the capabilities provided by the infrastructure provider and were resolved accordingly. One of the biggest challenges was designing the backup architecture within datacenter constraints, since local regulations required the platform to be hosted outside public cloud providers.
Defence in Depth: 7 Layers of Security
Defence in Depth: 7 Layers of Security
Security in this architecture was addressed in multiple layers beyond classical network isolation: Cluster boundary isolation,Network segmentation,East-West gateway control,mTLS service identity,Least-privilege data access, Kafka-based log consistency, Monitoring and traffic observability.

In conclusion, this journey was not merely about building a platform that satisfies regulatory requirements; it was a holistic transformation where architectural decisions were reshaped across security, operations, and sustainability dimensions. At the point we have reached today, the architecture we built provides not only a foundation that meets current PCI DSS requirements but also one that can readily adapt to future regulatory and licensing needs. This is the result of treating security as an inseparable part of design rather than an afterthought. I would like to extend my gratitude first and foremost to my teammates Moray Baruh and Batuhan Kertmen, as well as to the entire DevOps and Development teams, and our Chief of Architect Bora Gönül, for their invaluable contributions and supports.