Scheduling Tasks in Spring Boot: Vanilla way
Scheduling Tasks in Spring Boot: Vanilla way
In Spring Boot, task scheduling is a powerful feature that allows you to run specific functions at regular intervals. By using the @Scheduled annotation, you can easily define tasks to execute with a fixed delay, at a fixed rate, or according to a cron schedule. This built-in scheduling mechanism is sufficient for many use cases where tasks need to be executed periodically without any concurrency concerns.
To get the most out of this guide, it’s essential to understand the basics of Spring Boot’s out-of-the-box scheduling. For a detailed implementation guide, you can refer to this Baeldung Article. This will provide you with the foundational knowledge needed before diving into more advanced scheduling techniques discussed here.
Scheduling with concurrency control
Scheduling with concurrency control
Shedlock provides an easy way to prevent the concurrent executions of tasks using a data store. It supports any database with a JDBC driver, along with Mongo, Redis, Hazelcast, and Zookeeper.
Using @SchedulerLock annotation along with @Scheduled we can apply a lock with a name and minimum-maximum lock times.
Even though scheduler lock can be used for dynamically scheduled tasks the library is not designed for this purpose.
Also, what happens when you want your end-users or back office to schedule new jobs dynamically? What can you do to recover tasks that were scheduled for a time when the server was down?
That’s where quartz comes in. While it may be true shedlock is a simpler alternative to quartz in most cases. In more complex use cases we need to be able to utilize the mature library, Quartz.
Quartz
Quartz
According to the official website of quartz, “Quartz is a richly featured, open source job scheduling library that can be integrated within virtually any Java application — from the smallest stand-alone application to the largest e-commerce system”. For us, it differs from other scheduling libraries with its configurability, JTA transactions, and comprehensive clustering support.
Quartz Configuration
Quartz Configuration
Quartz advises their configurations to be placed in a quartz.properties file. However, this approach may not be suitable for some cases. You can also place your quartz configuration under spring.quartz.properties, in your application.properties or application.yml file (which we decided was cleaner, since you can re-use some values).
Even though quartz is thoroughly configurable there are no required values. To show an example we will change some values that don’t determine functionality.
org.quartz.scheduler.instanceName = QuartzIsAwesomeorg.quartz.scheduler.threadName = AwesomeSchedulerThreadorg.quartz.scheduler.instanceId = AUTOWe can’t stress enough how much quartz is configurable. So check out the configuration reference ASAP.
Sample usage
Sample usage
We will be using Kotlin on Java version 21, and Quartz 3.2.0 throughout this guide for the code demos.
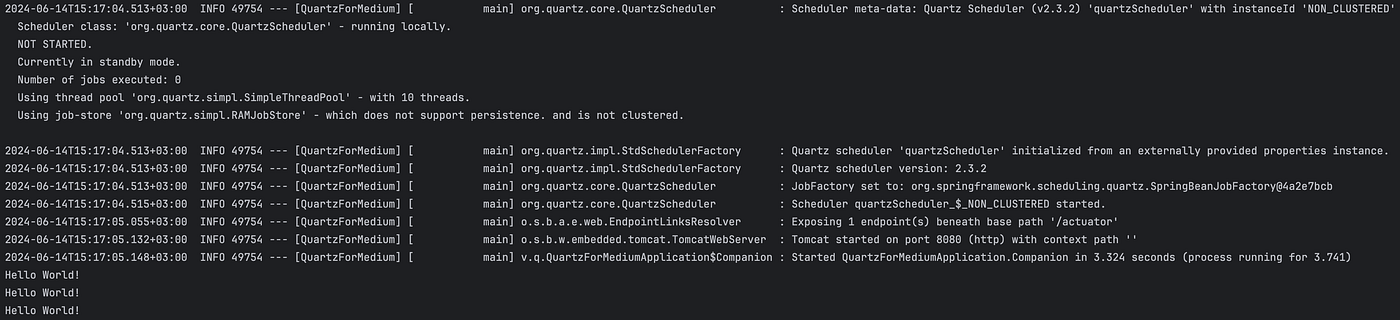
Now we will create our first Hello World! scheduled job. This example may seem convoluted compared to the one in the official documentation (Check it out first!) but we are setting our foundation for something bigger.
In quartz, tasks are expressed through Job interfaces of the quartz library. We implement these interfaces and fill out the execute function to our liking.
class VanillaQuartzJob : Job { override fun execute(p0: JobExecutionContext?) { println("Hello World!") } }We defined our job to simply print Hello World. But we were talking about executing arbitrary code on a schedule. We will accomplish that by using Quartz’s scheduler.
Since we were rooting for scheduling closer to spring @Scheduled annotation, we will not simply do the creating of schedules in a main function.
We will open a service named JobSchedulerService, then we can inject the scheduler spring will have been initialized for us. As you can see with the construction of this service we call scheduler.start() and preDestroy we call scheduler.shutdown(). Quartz schedulers do not execute jobs if they are not started (they may be on hold, not started, or stopped completely too).
@Service class JobSchedulerService(private val scheduler: Scheduler) { @PostConstruct fun init() { scheduler.start() } @PreDestroy fun preDestroy() { scheduler.shutdown() }}Now that we have access to our scheduler, we want to build a trigger. Quartz handles the scheduling of jobs through trigger entities. Triggers have different schedules and properties. This allows dynamically assigning 1 (job) to N (trigger) job-trigger relations, with @Scheduled we could only define a single schedule per job and never change it.
But we first need to create a JobDetail object. Quartz doesn’t keep hold of actual job objects but their information, as long as quartz has the class name it can later on access the execute method.
val jobDetail = JobBuilder.newJob(VanillaQuartzJob::class.java) .withIdentity("HelloWorldJob", "HelloWorldGroup") .storeDurably() .build()We said that we could dynamically assign multiple triggers to a job. But Quartz determines that a job that has no triggers pointing to it, is orphaned. And it will delete relevant information of it sometime later. However, we are sure our job will be used later so we used .storeDurably on the builder. Now that we have a way to provide the job information to Quartz we need to define a schedule through a trigger.
val trigger = TriggerBuilder.newTrigger() .withIdentity("HelloWorldTrigger", "HelloWorldGroup") .forJob(jobDetail) .withSchedule(CronScheduleBuilder.cronSchedule("*/5 * * * * ?")) .build()As you can see we created a schedule with a cron expression, which will tell the scheduler to fire this trigger every 5 seconds.
Ok so there are a lot of things going on but we only need simple schedules like @Scheduled does. So let’s extract the creation of triggers and JobDetails to a helper function.
fun schedule(clazz: Class<out Job>, jobName: String, jobGroup: String, cronExpression: String) { val jobDetail = JobBuilder.newJob(clazz) .withIdentity(jobName, jobGroup) .storeDurably() .build() val trigger = TriggerBuilder.newTrigger() .withIdentity(jobName, jobGroup) .withSchedule(CronScheduleBuilder.cronSchedule(cronExpression)) .build() scheduler.scheduleJob(jobDetail, trigger) }We simply used jobDetail’s identifier for the trigger too. After the creation of the trigger and job detail is complete we simply call scheduler.scheduleJob
@EventListener(ApplicationReadyEvent::class) fun onApplicationReady() { schedule(VanillaQuartzJob::class.java, "vanillaQuartzJob", "vanillaQuartzJobGroup", "*/5 * * * * ?") }And now we can automatically schedule the job on start-up.
And thus we have a code running every 5 seconds. Now we will get into more complex scenarios.
Dynamic scheduling
Dynamic scheduling
data class JobDetailDTO( var jobName: String, var jobGroup: String, var jobClass: String, var cronSchedule: String)@RestControllerclass JobSchedulerController( private val jobSchedulerService: JobSchedulerService) { @PostMapping("/jobs/add") fun addJob(@RequestBody jobDetailDTO: JobDetailDTO) { @Suppress("UNCHECKED_CAST") jobSchedulerService.schedule( Class.forName(jobDetailDTO.jobClass) as Class<out org.quartz.Job>, jobDetailDTO.jobName, jobDetailDTO.jobGroup, jobDetailDTO.cronSchedule ) } @PostMapping("/jobs/remove") fun removeJob(@RequestBody jobDetailDTO: JobDetailDTO) { jobSchedulerService.scheduler.deleteJob(JobKey.jobKey(jobDetailDTO.jobName, jobDetailDTO.jobGroup)) }}In the given code we provide a way to schedule new jobs through a REST API.
{ "jobName": "a", "jobGroup": "default", "jobClass": "org.valensas.quartzformedium.service.VanillaQuartzJob", "cronSchedule": "*/5 * * * * ?"}When we send a request with this JSON body we can see that now the “Hello World!” text is printed twice every second. But when we send the request again we see that we get an error:
Unable to store Job : 'default.a', because one already exists with this identification. This is natural. Job keys exist for a reason. We can make this endpoint override the existing job or return a warning. It is a design choice. However, we saw that we can dynamically create new schedules for predefined jobs.Let’s widen the scale a bit more.
Listeners
Listeners
We can implement listeners to react to events related to jobs and triggers. Let’s say we want to make sure all our job activities are logged. Instead of writing logs in all job execution functions two things come to mind first:
- Extend the Job interface in an abstract class and wrap the execute function with logs, catch and rethrow errors, etc.
- Use the listeners provided by quartz
As you can probably guess first approach becomes cumbersome when other moving parts get in or somebody forgets to use the modified class etc. The second approach is both easier and more robust.
class JobExecutionLogger : JobListener { private val logger = LoggerFactory.getLogger(javaClass) override fun getName(): String { return "JobExecutionLogger" } override fun jobToBeExecuted(p0: JobExecutionContext?) { logger.info("Job to be executed") } override fun jobExecutionVetoed(p0: JobExecutionContext?) { logger.info("Job execution vetoed") } override fun jobWasExecuted(p0: JobExecutionContext?, p1: JobExecutionException?) { logger.info("Job was executed") } }Here we have a proof of concept logging implemented. We could execute any arbitrary code but this is our example.
2024-06-14T16:10:10.002+03:00 INFO 51511 --- [QuartzForMedium] [eduler_Worker-6] o.v.q.service.JobExecutionLogger : Job to be executedHello World!2024-06-14T16:10:10.003+03:00 INFO 51511 --- [QuartzForMedium] [eduler_Worker-6] o.v.q.service.JobExecutionLogger : Job was executedNow we can see when the job was fired and when it finished. We could do more complex things like metrics etc.
We can even listen to what the scheduler does. Check out the documentation.
Job Stores
Job Stores
We mentioned clustered mode while talking about Quartz’s advantages. We need a central source of information if we want multiple instances from different machines to follow the same guidelines to schedule and execute jobs. So quartz uses job stores.
CAUTION: Never use a job store class directly, leave it to Quartz to handle the job store. You only need to configure it. We should indicate our purposes through scheduler
RAMJobStore
RAMJobStore
We were already using a job store, a RAM Job Store to be exact. The documentation describes it as:
RAMJobStore is the simplest JobStore to use, it is also the most performant (in terms of CPU time). RAMJobStore gets its name in an obvious way: it keeps all of its data in RAM.If there are no restrictions and no specified jobstore preference, quartz will use RAMJobStore by default.
JDBCJobStore
JDBCJobStore
JDBCJobStore class of quartz allows persisting jobs in almost every JDBC-compliant database. Documentation reports that quartz has been used widely with “Oracle, PostgreSQL, MySQL, MS SQLServer, HSQLDB, and DB2”.
Ok, then we want to go clustered mode and use a central jdbc database to store our jobs’ details.
To switch to the jdbc job store we need to configure it for both spring and quartz.
After we configure our database connection for spring, we need to choose between two implementations of the JDBCJobStore class: JobStoreTX and JobStoreCMT.
To summarize the documentation, JobStoreTX lets Quartz handle its db transactions by itself while JobStoreCMT leaves it to the app server container to manage it in the execution context (This means you can control when to commit or rollback transactions regarding Quartz job store).
For example, if we would use our schedulers mainly through rest apis it may be a good idea to use JobStoreCMT to satisfy data integrity.
To configure,
We simply add this:
org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTXor this:
org.quartz.jobStore.class: org.quartz.impl.jdbcjobstore.JobStoreTXunder our spring.quartz.properties (or quartz.properties file if you are using one)
Configuration, Resource Usage, and SchedulerFactory
Configuration, Resource Usage, and SchedulerFactory
Quartz’s architecture is modular, requiring several components to be configured before it can function. Fortunately, there are helpers to simplify this process.
Major Components to Configure:
Major Components to Configure:
- ThreadPool: Provides a set of threads for Quartz to use when executing jobs. The number of threads should balance between being small to conserve resources and large enough to ensure jobs fire on time.
- JobStore: Manages how job and trigger information is stored. Quartz offers various job stores, including in-memory and database-backed options.
- DataSources: Required if you are using a JDBC-backed job store.
- Scheduler: The main Quartz component that needs a name, RMI settings, and instances of JobStore and ThreadPool.
ThreadPool
ThreadPool
The ThreadPool interface is in the org.quartz.spi package, and you can implement it as needed. Quartz includes a robust implementation called org.quartz.simpl.SimpleThreadPool, which maintains a fixed number of threads. The size of the thread pool depends on your scheduling needs, with most users finding 5 threads sufficient, but larger deployments may require more.
JobStores and DataSources
JobStores and DataSources
All JobStores implement the org.quartz.spi.JobStore interface. If the provided JobStores do not meet your needs, you can implement your own.Scheduler
Scheduler
Creating a Scheduler instance involves giving it a name, RMI settings, and instances of a JobStore and ThreadPool. The StdSchedulerFactory can create Scheduler instances and initialize them with the necessary components.StdSchedulerFactory
The StdSchedulerFactory uses properties (typically stored in a file) to create and initialize a Quartz Scheduler. Calling getScheduler() on the factory will produce and initialize the scheduler, its ThreadPool, JobStore, and data sources.DirectSchedulerFactory
The DirectSchedulerFactory allows for programmatic creation of Scheduler instances but is generally discouraged due to its complexity and the need for hard-coded settings.Logging
Logging
Quartz uses the SLF4J framework for logging. You can tune logging settings via the SLF4J configuration. For capturing detailed information about job and trigger executions, consider enabling org.quartz.plugins.history.LoggingJobHistoryPlugin and org.quartz.plugins.history.LoggingTriggerHistoryPlugin.For more detailed configurations, refer to the configuration reference.
Clustering
Clustering
Clustering in Quartz is currently supported with the JDBC-Jobstore (JobStoreTX or JobStoreCMT) and the TerracottaJobStore. Clustering provides features like load-balancing and job fail-over if the JobDetail's "request recovery" flag is set to true.Clustering with JobStoreTX or JobStoreCMT To enable clustering, set the org.quartz.jobStore.isClustered property to true. Each instance in the cluster should use the same copy of the quartz.properties file, with the following exceptions: different thread pool size and different values for the org.quartz.scheduler.instanceId property. Each node in the cluster must have a unique instanceId, which can be easily set by using AUTO as the value of this property.
Important Considerations for Clustering:
Important Considerations for Clustering:
- Ensure all clustered nodes have synchronized clocks. Use a time-sync service to keep clocks within a second of each other.
- Do not run a non-clustered instance against the same database tables used by clustered instances to avoid data corruption and erratic behavior.
- Only one node will fire a job for each trigger, though the specific node may vary. The load balancing mechanism is near-random for busy schedulers but favors the most recently active node for less busy schedulers.
Clustering with TerracottaJobStore: Just configure the scheduler to use TerracottaJobStore. Additionally, consider how you set up your Terracotta server, including configuration options for persistence and high availability (HA).
JTA transactions
JTA transactions
JobStoreCMT allows Quartz scheduling operations to be part of larger JTA transactions. You can execute jobs within a JTA transaction by setting the org.quartz.scheduler.wrapJobExecutionInUserTransaction property to true. This starts a JTA transaction just before the job's execute method is called and commits it right after the method terminates. This setting applies to all jobs.
For per-job JTA transaction control, use the @ExecuteInJTATransactionannotation on the job class.
Scheduler interface calls also participate in transactions when using JobStoreCMT. Ensure a transaction is started before calling scheduler methods, either directly through UserTransaction or by placing your scheduler-using code within a SessionBean that uses container-managed transactions.Miscellaneous Features
Miscellaneous Features
Plug-Ins
Plug-Ins
Quartz provides an interface, org.quartz.spi.SchedulerPlugin, for adding additional functionality to the scheduler. Plugins can perform a variety of utility functions such as:- Auto-scheduling of jobs upon scheduler startup.
- Logging a history of job and trigger events.
- Ensuring the scheduler shuts down cleanly when the JVM exits.
These built-in plugins are documented in the org.quartz.plugins package.JobFactory
JobFactory
When a trigger fires, the associated job is instantiated via the JobFactoryconfigured on the scheduler. The default JobFactory simply calls newInstance() on the job class. However, you may want to create your implementation of JobFactory to integrate with your application’s IoC (Inversion of Control) or DI (Dependency Injection) container, allowing it to produce and initialize the job instance.
Refer to the org.quartz.spi.JobFactory interface and the Scheduler.setJobFactory(fact) method for details on creating and setting a custom JobFactory.Factory-Shipped Jobs
Factory-Shipped Jobs
Quartz includes several utility jobs that you can use in your application. These jobs perform common tasks such as sending e-mails and invoking EJBs. These out-of-the-box jobs are documented in the org.quartz.jobspackage.Simply Quartz
Simply Quartz
Quartz has many great features. However, we saw that there was a lot of code duplication for simple job schedules like cron or simple intervals. We extracted parts that we could generalize and wrote a quality-of-life library that let us utilize quartz while defining jobs in springs simple annotation style.
Check it out.
Before Simply Quartz:
Before Simply Quartz:
@Scheduled(cron = "0 15 0 15 * ?")fun schedule() { println("Scheduled task")}After Simply Quartz:
After Simply Quartz:
@QuartzSchedule(cron = "0 15 0 15 * ?")@DisallowConcurrentExecutionclass SampleJob : Job { override fun execute(context: JobExecutionContext?) { println("Scheduled Task") }}
As you can see we define jobs more simply like the vanilla spring scheduled jobs, meanwhile we could use quartz’s @DisallowConcurrentExecution.We can also utilize any quartz feature that we already talked about. Clustered job execution is the most crucial part of quartz and we can easily access it without defining separate services for the creation and updating of jobs and triggers. That’s the part Simply Quartz handles.
We still need to configure quartz just like we did before since all the infrastructure is handled by quartz.
What does Simply Quartz do in the background?
What does Simply Quartz do in the background?
At application start-up, simply quartz searches for classes that implement the Job interface of quartz, which are also annotated with @QuartzSchedule annotation.
This is done by using the reflections module, and we can denote certain packages to be scanned to not overwhelm our application if the source code is big.
After finding those classes, Simply Quartz keeps a list of which jobs are new, updated or to be deleted. Then it completes all updates and creations, if those succeed deletions are done. This methodology ensures any runtime errors do not cause important jobs that should not miss their schedule to be hanging until someone realizes a crash occurred during job creation.
You might be asking if we are not solving a problem that we created. That is not the case since quartz auto initialization of schemas drops all the tables, and then through the code we wrote the jobs are scheduled. But if our code fails some jobs may never be scheduled until someone solves the error.
That’s why we let migrations (or any method you prefer) handle the database initialization and updates, and simply quartz handles the automatic scheduling and updating of jobs in a robust way.
Extra features
Extra features
We added another class that implements Job, named TimedJob. It behaves exactly like a function annotated with micrometers @Timed annotation. This class works out of the box if you set up your micrometer registry correctly.
Note: TimedJob uses the global meter registry of micrometer and custom tags for “jobname”, “jobgroup”, and “exception”.
Check out Simply Quartz for the documentation and source code.